According to Gartner, cloud computing will become an essential component of maintaining business competitiveness by 2028. Indeed, in 2024 spending on public cloud services is projected to reach $679 billion. While cloud spend is complex and costs originate from a number of sources, it is undeniable that many organizations are moving apps and services to the cloud and using Kubernetes to manage containers effectively and ensure workload reliability.
Using data from over 330,000 workloads and hundreds of organizations, Fairwinds created the 2024 Kubernetes Benchmark Report, which analyzes trends in 2024 and compares the results to 2022 and 2023 benchmarks. Even though organizations are already deploying Kubernetes workloads in production, many still face challenges with aligning to Kubernetes best practices. Unfortunately, lack of alignment may result in significant consequences: increased security risks, out-of-control cloud costs, and reduced reliability for apps and services. The benchmark analysis reviewed all of these topics, while this post focuses on six areas related to workload reliability to help you identify areas where you’re doing well or need to make some improvements.
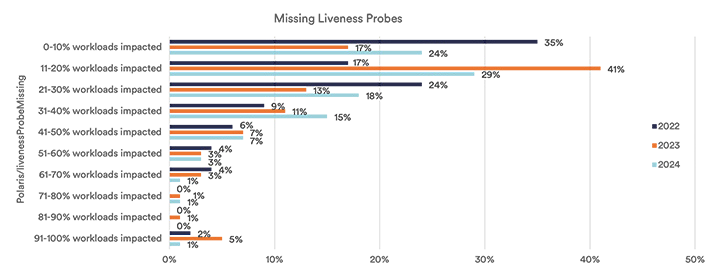
A liveness probe indicates whether a container is running or not, which is a fundamental indicator of whether a Kubernetes workload is functioning as designed. If a liveness probe moves into a failing state, Kubernetes sends a signal to restart the container automatically. The goal of restarting the container is to restore the service to an operational state. However, if you haven’t ensured that each container in the pod has a liveness probe, the non-functioning container is likely to run indefinitely, using resources and, in some cases, causing application errors.
Similarly, readiness probes indicate whether a container is ready to receive traffic, which also impacts overall reliability of an application. Inevitably, containers fail and need to be restarted, and Kubernetes liveness and readiness probes play a significant role in ensuring that containers are available and ready to serve traffic when that happens. Based on the benchmark, the latest data shows that 69% of organizations have between 11-50% of workloads missing liveness probes. Similarly, we see 66% of organizations with 11-50% of workloads missing readiness probes. Have you ensured that your workloads have liveness and readiness probes in place?
In Kubernetes, a pull policy is a setting that determines how and when Kubernetes pulls container images for your pods. It tells the Kubernetes worker nodes (kubelets) how to handle image downloading when running a pod. Unfortunately, relying on cached Docker images can result in reliability and security issues. By default, Kubernetes pulls an image if the image is not already cached on the node that is trying to run it. If you use a cached version, though, it can result in multiple versions of an image running per node. It can also introduce potential security vulnerabilities, primarily because Kubernetes will use the cached version of an image without verifying its origin. The 2024 Benchmark shows an increase in the number of workloads impacted: 24% of organizations rely on cached images for more than 90% of workloads, which may significantly impact the reliability of applications.
The Benchmark report began including missing replicas in its analysis in 2023 because we discovered that many workloads were not configured with a replica. In 2024, 55% of organizations had more than 21% of workloads missing replicas. Replicas help maintain the stability and availability of containers because a ReplicaSet will replace failed pods. What percentage of your workloads have missing replicas?
The latest benchmark data shows that more organizations are setting CPU limits. Analysis shows that 22% of organizations have less than 10% of workloads missing CPU limits. When you do not specify CPU limits, the container does not have any upper bound, which is a problem because CPU intensive containers may use all CPU available on the node, thereby starving other containers of the resources they need. Setting CPU limits helps increase the cost efficiency and reliability of applications, so it’s worthwhile to check that they are in place and appropriately set.
Looking at the new data, it appears that organizations are realizing the value of ensuring that CPU requests are set. In 2022, only 50% of organizations were missing requests on at least 10% of their workloads while 78% of organizations were missing requests on at least 10% of workloads in 2023. This year, it’s down to 67% of organizations that have 10% or more workloads impacted by missing CPU requests.
Similar to CPU limits, if you don’t have CPU requests set, a single pod may be able to consume all of the node CPU and memory, thereby starving other pods for resources. When you set resource requests it guarantees that the pod will have access to the resources needed. This helps ensure greater reliability for your apps and services.
Kubernetes brings extraordinary value to organizations in 2024 and beyond, which means that understanding the many configurations available in Kubernetes and how to adjust them appropriately is critical if you want to meet your environment and business requirements. The Kubernetes Benchmark report can help you understand where your peers are succeeding and failing in configuring their workloads and whether they are consistently aligning to best practices. Use this information to help you configure your deployment such that it is as secure, reliable, and cost-efficient as possible.
Read the Kubernetes Benchmark Report today.