
Experienced Kubernetes cluster operators know that upgrades can be tricky. Tools like kops try to make this process better, but it's not yet a solved problem. Cluster upgrades can be scary - even dangerous. At Fairwinds, we do a lot of cluster upgrades and customers rely on us to get them right. When we say we do a lot, we're talking about at least 2 clusters per customer (often more than 2), and we update them around 4 times a year. This means we babysit a lot of rolling updates, which gives us plenty of chances to reflect and strategize. We’ve come up with a few tricks to make the process better, and we’ve compiled them here to share with you.
First, let’s review current state with kops since the majority of our clusters are managed by it. The rolling update strategy is documented here, and works like this:
For each node:
1. Drain the node
2. Terminate the EC2 instance
3. Wait for a replacement node in the ASG (Autoscaling Group) to join the cluster
4. Wait for the cluster to be validated
There are a couple of issues with this update strategy. These issues become far more problematic as clusters get larger:
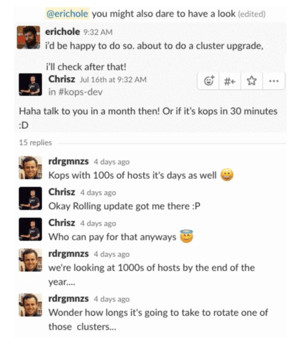
The first issue involves draining the nodes and shuffling the Pods around. When Kubernetes drains a node in preparation for deletion, it has to reschedule whatever workload was running. If you look carefully at the example above, you’ll notice that Pods are frequently getting moved multiple times! For the first node, every rescheduled Pod will need to be moved at least 1 more time. The chance that a pod gets rescheduled multiple times gets better as time goes on, but this is not a workable long-term scheduling strategy. This is kind of silly because we know which nodes are going away ahead of time.
Second, waiting for a node to get deleted, a new node to start and then join the cluster can take up to 10 minutes. When you have clusters that are 20 or more nodes, this process can take hours.
If your apps are resilient, and politely shut down when asked to do so, this shuffle is mostly just annoying. If you have apps that don’t play nice, this can create actual problems. It magnifies the time it takes to do the upgrade.
In the cloud, running extra instances for a short period of time is relatively cheap. At Fairwinds, we propose to spend more of our abundant compute resources to retain our scarcest resource: time.
We start the upgrade process by the books: we use the rolling update process for the masters. This drains and replaces instances, one by one. Then, we put our twist on it.
For each “node” instance group:
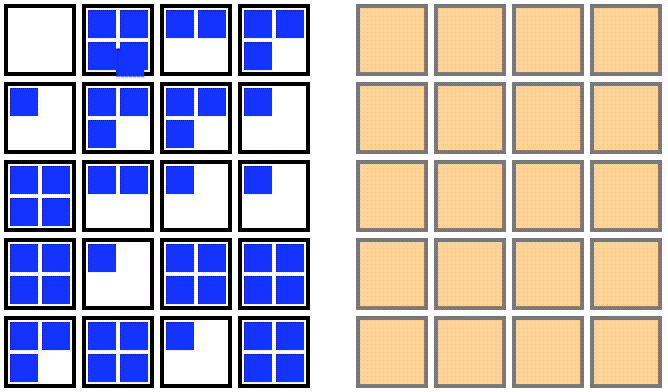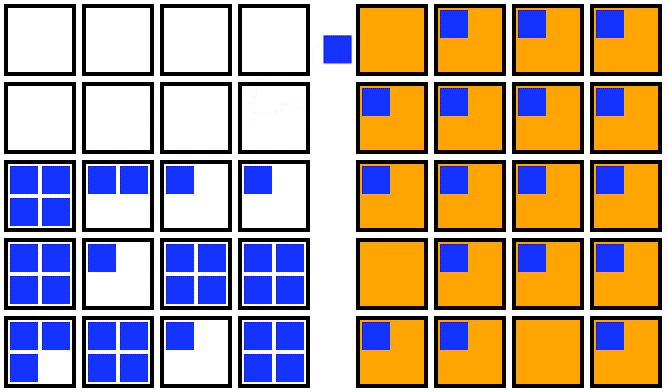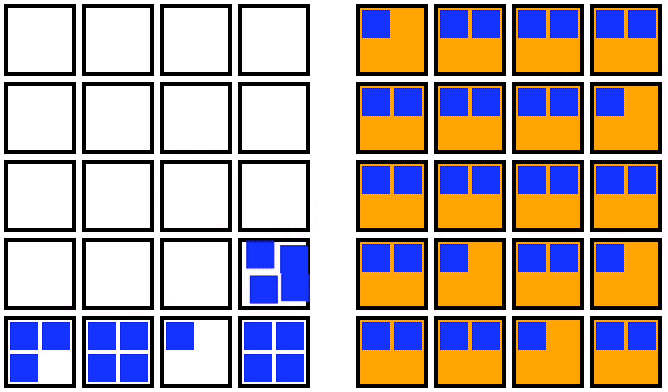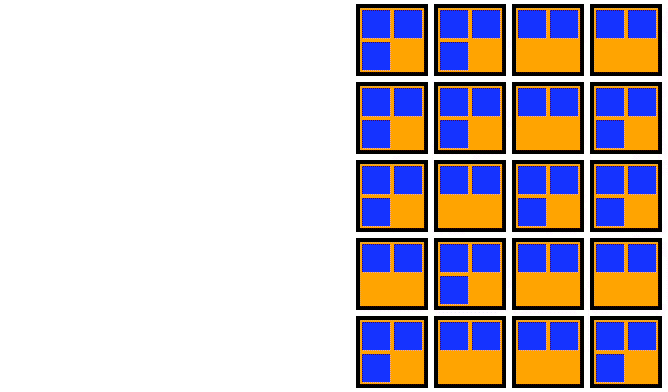
1. Double the number of nodes
2. Cordon the old nodes
3. Drain the old nodes
4. Terminate those nodes
This is significantly faster than a rolling update. It parallelizes the startup of the nodes so it all happens at once. This has a wonderful side effect: it gives you tons of space to schedule all those Pods that you’re about to drain. Then all of the nodes that are done accepting traffic are cordoned at once. This means you only have to find a home for your Pods once. That’s pretty cool.
Once the masters are updated, the process is pretty straightfoward, but we’ve laid out the steps below so you can avoid some of the less obvious prob arise.
1. Disable cluster autoscaler if it’s installed. This is not optional. Do your upgrade when your traffic is expected to be relatively consistent and ideally minimal. That’s when you do all your upgrades anyway, right? :) If you don’t disable it, cluster-autoscaler really wants to delete all your new nodes because they’re all empty. We find scaling the cluster-autoscaler to 0 replicas sufficient.
2. Double the cluster size. This can be done a few ways, but the simplest is to edit the autoscaling group (or kopsinstance group). New nodes will initialize with the new launch configuration and the new version of Kubernetes Run kubectl get nodes to see all the nodes on the new version.
3. If you are using ELBs, take a moment here to validate that your new nodes are <strong>Healthy</strong> in the ELB.
This is important because a node that is marked as SchedulingDisabled is considered unavailable and will be taken out of an ELB that it is attached to. If we cordon all the old nodes before new nodes get added to the ELB, this will cause outages.
4. If you are using <strong>externalTrafficPolicy: Local</strong> on any of your<strong>LoadBalancer</strong>-type <strong>Services</strong>, it is important that you temporarily set<strong>externalTrafficPolicy: Cluster</strong> before you move on.
If we cordon all the old nodes before one of the Pods in that Service is available on a new node, we're guaranteed to have 0 Healthy nodes in the ELB and have an outage. If setting externalTrafficPolicy: Cluster temporarily isn't an option for you, make sure to get a Pod running on a new node before continuing.
5. Cordon all the old nodes.
If you’re upgrading versions, use a command like kubectl get nodes | grep <old version> | awk '{print $1}' | xargs kubectl cordon to quickly target only the old nodes. This is how we prevent Pods from being rescheduled more than once.
6. Drain the old nodes.
Now that we have all the old nodes cordoned and empty scheduling space equal to the space that is being taken out of service, draining the old nodes will reschedule everything from old nodes to new nodes. We have found something like the following to be useful: kubectl get nodes | grep SchedulingDisabled | awk '{print $1}' | xargs kubectl drain --ignore-daemonsets --delete-local-data --force
7. Turn cluster-autoscaler back on!
The old nodes are empty, we don’t need them anymore. Cluster-autoscaler makes quick work of them.
PSA: It may be a good time to verify that all those random third party bits in kube-system that you've installed over who knows how long are still working and you're still running an appropriate version, given your new version of Kubernetes.
There is an open PR on the kops repo that introduces this exact strategy as well as others, and will hopefully be available within the next few versions. Until then, we’ve found all of this to be useful and we hope you do too!

